When using Kubernetes, it is mandatory to collect performance metrics so as to be able to plot them into meaningful graphs (a must-have during troubleshooting), visualize alerts in dashboards and get email notification of critical events. The best practice is to deploy Prometheus, Grafana and Alertmanager.
In the "Kubernetes Prometheus And Grafana With kube-prometheus-stack" post we see how to easily deploy and setup these three amazing components to setup a full featured alerting and performance monitoring solution.
The post also shows how to deploy additional Grafana Dashboards and how to deploy custom Prometheus rules to trigger application specific alerts.
What Is kube-prometheus-stack
The kube-prometheus-stack is not just an easy way not only to deploy Prometheus, Prometheus' Alertmanager and Grafana on Kubernetes: it also provides a collection of Kubernetes manifests, Grafana dashboards, and Prometheus Rules enabling to easily operate end-to-end Kubernetes cluster monitoring with Prometheus using the Prometheus Operator.
Luckily, they also provide an Helm chart to easily deploy it - please mind it has a dependency on the Grafana Helm chart.
Configure Helm
In this post I'm showing how to deal with this using the "helm" command line utility, but the same procedure can be used also with tools (such as Rancher), providing Helm's features through a UI.
In a clean and tidy setup, it's best to have a directory dedicated to the Helm's values files for each distinct deployment - just create the directory as follows:
mkdir ~/deploymentsThe purpose is having a common place where to store the values files for each single instance we deploy, so to easily deploy them again is necessary later on, for example to upgrade the containers, to apply the enhancement of an upgraded Helm chart or even just to change some settings.

Although this is not necessary for running Helm, it is wise to create a git repository within the "~/deployments" directory, so to be able to easily rollback configuration changes if anything would go wrong.
cd ~/deployments; git initAnd of course configure it to push the commits to a remote repository. For more information on how to professionally operate with Git, you may want to read my post "GIT Tutorial - A thorough Version Control with Git Howto".
Add The Grafana Helm Repository
First, add the Grafana Helm chart's repository "https://grafana.github.io/helm-charts" as follows:
helm repo add grafana \
https://grafana.github.io/helm-chartsAdd The Prometheus Helm Repository
Once done, since the "kube-prometheus-grafana" Helm chart has a dependency on the official Grafana project's Helm chart, we must then add the official Prometheus Community Helm chart's repository "https://prometheus-community.github.io/helm-charts" as well:
helm repo add prometheus \
https://prometheus-community.github.io/helm-chartsSetup kube-prometheus-stack
Now that Helm has properly been configured for fetching the necessary Helm charts, it is time to create the "kube-prometheus-stack" Helm's values file.
Grab A Copy Of The kube-prometheus-stack Values File
The most safe option, so to have it perfectly matching the latest available Helm chart version we are installing, is to download the helm chart itself to a local directory as follows:
helm pull prometheus/kube-prometheus-stack \
--untarand then move the values.yaml file to the "~/deployments" directory previously created - please note how we are also renaming it meaningfully:
mv kube-prometheus-stack/values.yaml \
~/deployments/kube-prometheus-stack.yamlunless we want to study this Helm chart's role internals, the contents of the whole "kube-prometheus-stack" chart are not necessary. For this reason, we can remove the directory as follows:
rm -rf kube-prometheus-stackCustomize The kube-prometheus-stack Values File
At this point we finally have a copy of the value file we can customize to fit our needs.
Customize Prometheus
The default Prometheus configuration is almost suitable for every use case - the only missing bit is having the ingress rule automatically created during the deployment. We can achieve this by adding the missing bits as by the below snippet:
prometheus:
ingress:
annotations: {}
enabled: true
hosts:
- kube-p1-0.p1.carcano.corp
labels: {}
paths:
- /
- /alerts
- /graph
- /status
- /tsdb-status
- /flags
- /config
- /rules
- /targets
- /service-discoveryin this example the Prometheus URL's FQDN is "kube-p1-0.p1.carcano.corp", so - if you configured the load balancer and the Kubernetes Ingress controller as I described in the "RKE2 Tutorial - RKE2 Howto On Oracle Linux 9" post, Prometheus will be available at "https://kube-p1-0.p1.carcano.corp".
Customize Alertmanager
The next component to customize is Alertmanager - also in this case the default configuration is almost suitable for every use case - even here we are making a little bit of tuning to have the ingress rule automatically created during the deployment: just add the missing bits as by the below snippet:
alertmanager:
alertmanagerSpec:
...
routePrefix: /alertmanager
...
config:
...
receivers:
- name: 'null'
- email_configs:
- from: kube-p1-0@carcano.corp
require_tls: false
send_resolved: true
smarthost: mail-p1-0.p1.carcano.corp:587
to: devops@carcano.corp
name: global-email-receiver
...
routes:
- matchers:
- alertname = "Watchdog"
receiver: 'null'
- matchers:
- namespace != "preproduction"
receiver: global-email-receiver
...
ingress:
annotations: {}
enabled: true
hosts:
- kube-p1-0.p1.carcano.corp
labels: {}
paths:
- /alertmanagerthe Alertmanager tweaking is a little bit more complex:
- we are configuring the ingress rule to publish it at "https://kube-p1-0.p1.carcano.corp/alertmanager" - FQDN is set at line 30, whereas the "/alertmanager" path is configured at line 33. In addition to that, alertmanager itself is configured to use "/alertmanager" as base path (line 4) - mind that it works only if you configured the load balancer and the Kubernetes Ingress controller as I described in the "RKE2 Tutorial - RKE2 Howto On Oracle Linux 9" post
- we add the "global-email-receiver" alert receiver capable to send email notifications to "devops@carcano.corp" using "kube-p1-0@carcano.corp" as sender email address relying through the "mail-p1-0.p1.carcano.corp" SMTP server on port "587" (lines 10-16)
- configure a matching route that routes to the "global-email-receiver" alert receiver every alert except the ones coming from the "preproduction" namespace (lines 22-24)
The above snippet provides the Alertmanager configuration hardcoded in the Helm Chart. It is anyway possible to provide it as a standalone YAML manifest of kind "AlertmanagerConfig". In this case, it is necessary to provide the Alertmanager's manifest name as "alertmanager.alertmanagerSpec.alertmanagerConfiguration", for example:
alertmanager:
...
alertmanagerSpec:
...
alertmanagerConfiguration:
name: global-alertmanagerconfigBe wary that despite being similar, Alertmanager configuration uses snake_case, whereas by the manifest of kind AlertmanagerConfig uses camelCase.
Customize Grafana
The last component we have to customize is Grafana: this component requires a little bit more tweaking. For example, since it supports authentication and authorization, it is certainly worth the effort to enable LDAP authentication.
In this example we are connecting to the LDAP service of an Active Directory server.
To guarantee the confidentiality of the transmitted data, we use LDAPS: this requires to first load a copy of the CA's certificate that issued the Active Directory service certificate into a configMap:
kubectl -n monitoring create configmap \
certs-configmap --from-file=my-ca-cert.pemOnce done, modify the Grafana part of the values file adding the below snippet:
grafana:
adminUser: admin
adminPassword: prom-operator
ingress:
enabled: true
hosts:
- kube-p1-0.p1.carcano.corp
path: /grafana/
pathType: Prefix
extraConfigmapMounts:
- name: certs-configmap
mountPath: /etc/grafana/ssl/
configMap: certs-configmap
readOnly: true
grafana.ini:
auth.ldap:
allow_sign_up: true
config_file: /etc/grafana/ldap.toml
enabled: true
log:
mode: console
server:
root_url: https://kube-p1-0.carcano.corp/grafana
serve_from_sub_path: true
ldap:
config: |-
verbose_logging = true
[[servers]]
host = "ad-ca-up1a001.p1.carcano.corp"
port = 636
use_ssl = true
root_ca_cert = "/etc/grafana/ssl/CACert.pem"
start_tls = false
ssl_skip_verify = false
bind_dn = "kube-p1-0@carcano.corp"
bind_password = 'aG0df-We6'
search_filter = "(sAMAccountName=%s)"
search_base_dns = ["dc=carcano,dc=corp"]
[servers.attributes]
name = "givenName"
surname = "sn"
username = "sAMAccountName"
member_of = "memberOf"
email = "mail"
[[servers.group_mappings]]
group_dn = "CN=Rancher-0-admins,OU=Groups,DC=carcano,DC=corp"
org_role = "Admin"
[[servers.group_mappings]]
group_dn = "CN=Rancher-0-operators,OU=Groups,DC=carcano,DC=corp"
org_role = "Editor"
[[servers.group_mappings]]
group_dn = "*"
org_role = "Viewer"
enabled: true
existingSecret: ''
as you can probably guess, if you configured the load balancer and the Kubernetes Ingress controller as I described in the "RKE2 Tutorial - RKE2 Howto On Oracle Linux 9" post, Prometheus will be available at "https://kube-p1-0.p1.carcano.corp/grafana".
The above sample configures Grafana to bind to the "ad-ca-up1a001.p1.carcano.corp" Active Directory as user "kube-p1-0@carcano.corp".
It also grants:
- administrative rights to the members of the "CN=Rancher-0-admins,OU=Groups,DC=carcano,DC=corp" Active Directory group
- "Editor" rights to the members of the "CN=Rancher-0-operators,OU=Groups,DC=carcano,DC=corp"
- "Viewer" rights to anyone else.
If you are dealing with an already deployed Grafana and you are looking for the administrative credentials, they are stored within the "kube-prometheus-stack-grafana" secret in the same namespace where "kube-prometheus-stack" is running. You can easily retrieve them as follows:
Username:
kubectl -n monitoring get secrets kube-prometheus-stack-grafana \
-o jsonpath="{.data.admin-user}" | base64 --decode ; echoPassword:
kubectl -n monitoring get secrets kube-prometheus-stack-grafana \
-o jsonpath="{.data.admin-password}" | base64 --decode ; echoDeploy kube-prometheus-stack
We are finally ready to deploy the "kube-prometheus-stack" - first, just run a dry-run to check that everything was properly configured:
helm install -f ~/deployments/kube-prometheus-stack.yml \
--dry-run prometheus prometheus/kube-prometheus-stackif the outcome is good (the Helm templates are properly rendered and printed to the standard output), then proceed with that actual deployment as follows:
helm install -f ~/deployments/kube-prometheus-stack.yml \
prometheus prometheus/kube-prometheus-stackand just wait until the deployment completes - if you are using git for versioning the values file, this is the time for committing the changes.
At the time of writing this post, the "kube-prometheus-stack" Helm chart (65.8.1) adds the unnecessary entry "k8s-app=kube-proxy" to the "kube-prometheus-stack-kube-proxy" service selector. Sadly this causes a mismatch resulting in no pods' endpoints bound to service, with the consequence of Prometheus not being able to scrape them, and so raising an alert in Alertmanager.
This can be easily checked by running:
kubectl -n kube-system describe svc \
kube-prometheus-stack-kube-proxy | grep SelectorIf the selector's output is different from:
Selector: component=kube-proxyThen you must remove any additional entry, leaving only the "component=kube-proxy" item.
Another cause of problems can be having the "kube-controller-manager", "kube-scheduler" and of course the "kube-proxy"endpoints bound to the host's loopback interface: this way they will be unreachable to Prometheus, causing alerts to be fired. The solution is starting them with the related option (such as "bind-address=0.0.0.0"), to prevent that strict binding: you can find examples in the "RKE2 Tutorial - RKE2 Howto On Oracle Linux 9" post.
Set Up Additional Rules
AlertManager Rules
The default Alertmanager configuration we provided sends email alerts for everything, inhibiting only the notification of the Watchdog rule - the watchdog rule is used only to make sure alerts are raised in Alertmanager - it's not a "real" alert.
If you want to have a more fine grained control on it, you can add namespace specific AlertmanagerConfig manifests with additional settings.
For example, the following manifest configures Alertmanager to notify "dba@carcano.corp" when alerts are raised in the "databases" namespace:
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: dba-alerts
namespace: databases
spec:
receivers:
- name: 'dba-email-receiver'
emailConfigs:
- to: 'dba@carcano.corp'
sendResolved: true
smarthost: 'mail-p1-0.p1.carcano.corp:587'
from: 'kube-p1-0@carcano.corp'
requireTLS: no
route:
groupBy: ['node']
groupWait: 30s
groupInterval: 5m
receiver: 'dba-email-receiver'
repeatInterval: 10m
matchers:
- name: alertname
regex: true
value: '.*'Prometheus Rules
It is of course possible to define custom Prometheus rules to trigger alerts on application specific events computed by checking application-specific metrics.
Just as an example:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
app: kube-prometheus-stack
app.kubernetes.io/instance: kube-prometheus-stack
release: kube-prometheus-stack
name: kube-prometheus-stack.carcano.rules.redis
namespace: cicd
spec:
groups:
- name: outages
rules:
- alert: RedisDown
expr: redis_up == 0
for: 0m
labels:
severity: critical
annotations:
summary: Redis down (instance {{ $labels.instance }})
description: "Redis instance is down\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
- alert: RedisRejectedConnections
expr: increase(redis_rejected_connections_total[1m]) > 0
for: 0m
labels:
severity: critical
annotations:
summary: Redis rejected connections (instance {{ $labels.instance }})
description: "Some connections to Redis has been rejected\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"the above manifest defines the "kube-prometheus-stack.carcano.rules.redis" Prometheus rule as follows:
- applies to the "cicd" namespace only (line9 )
- defines a group of rules called "outages" (lines 12 - 29) with the following alerts:
- RedisDown: triggered when the "redis_up" metric is equal to 0 (lines 14 - 21)
- RedisRejectedConnections: triggered when the "redis_rejected_connections_total" metric per each minute are greater than 0 (lines 24 - 29)
You can of course use the above example as the starting point for writing your own application specific Prometheus rule
Monitoring A Workload
Let's see a real-world example of adding performance monitoring to a shelf application deployed with an Helm chart.
The steps for enabling performance metrics collecting are:
- enable metrics - there is often a specific section in the Helm's values file - just look for it and set enabled to true.
- enable service monitor - there is often a specific section in the Helm's values file - just look for it and set enabled to true
Please make sure the label "release: kube-prometheus-stack" is really assigned to the service monitor - check it after the deployment of the Helm chart: if they are missing, Prometheus will ignore it.
You must then add a dashboard - the best practice is to look for an already existing one from, and only if it does not already exist, create your own, possibly starting from something quite similar already existent.
As an example, if you want to add the Grafana Redis HA Dashboard, first download its JSON file and rename it to "redis-ha-11835_rev1.json".
Then, add the "grafana-redis-ha" config map in the namespace of the monitored application, assigning it the label "grafana_dashboard=1", uploading the "redis-ha-11835_rev1.json" file into it.
Just wait a few, and the Dashboard will appear in the list of the available dashboards.
The Stack In Action
The "kube-prometheus-stack" is really an invaluable ally to monitor and detect problems: the most advanced dashboards do help you to make sense even of performance metrics tightly bound to the specific application business logic.
In our example setup you can access Grafana by connecting to the URL "https://kube-p1-0.p1.carcano.corp/grafana", logging in with your Active Directory credentials.
The below screenshot for example is of a KeyDB instance:

As you see it renders in a easy to understand way business-related metrics such as the number of keys for each db, the number of expiring and not expiring keys and so on - having such a detailed view can really save your life when things start going in an unexpected way, since they greatly help you in making sense of what's happening inside the application.
A very useful dashboard to see the lasting of problems is the "Alertmanager / Overview" - you can see an example from the below picture:
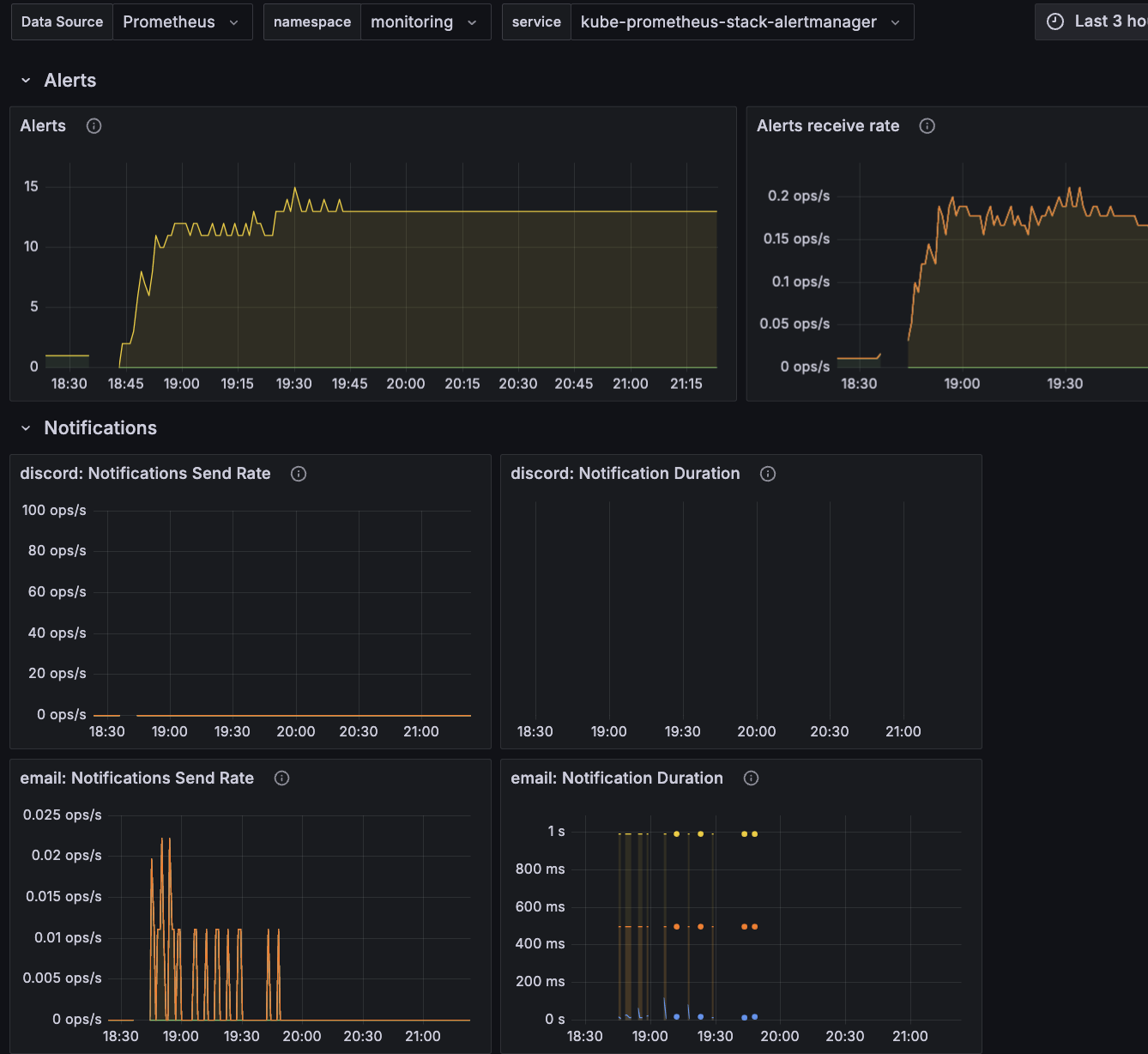
As you can see, it's showing a timeline with the number of alerts as well as the number of email notifications sent and their duration - these graphs are really useful when drawing up incident reports.
In the above example, you can immediately guess that something serious is happening, since the alerts suddenly raised in number and then stabilized.
Besides checking the notification emails, you can check the Alertmanager dashboard - in our setup you can access it by connecting to the "https://kube-p1-0.p1.carcano.corp/alertmanager" URL.
In the below picture is related to the situation depicted by the previous one:
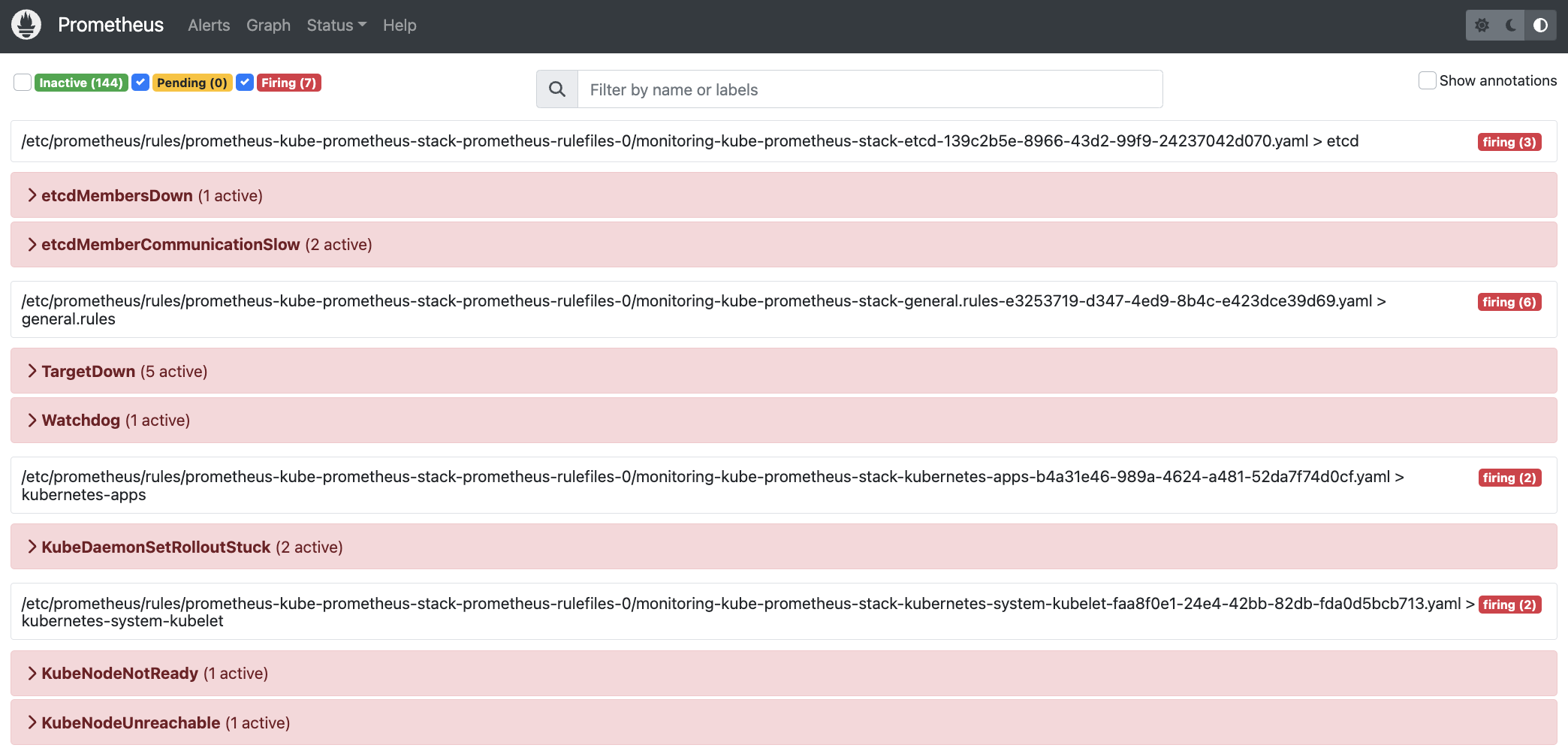
as you see there was really a huge accident: we lost a Kubernetes master node! You can guess that because of the etcd, KubeNode and KubeDaemonSetRollout alarms.
Footnotes
We have come to the end of this post. As you saw, deploying Prometheus and Grafana using the "kube-prometheus-stack" is really quite an easy walk: installing this amazing suite enables you to have an inexpensive yet very effective performance monitoring solution.
If you liked this post, … please give your tip in the small cup below:
