Every skilled professional should have an understanding of how the kernel does allocate memory: sooner or later it happens to get a system stuck complaining that it cannot allocate memory, despite the output of the "free" command showing that there's plenty of memory. This can get people confused, however this only means that the system cannot allocate kernel memory, despite it can still allocate system memory. The aim of this post is to clarify how the kernel allocates physical memory using the buddy algorithm, along with the available tools to check the state of physical memory.
The Buddy Memory Allocation Algorithm
Probably one of the most detailed explanations of the buddy algorithm is the one provided by Donald E. Knuth in the first volume ("Fundamental Algorithms") of "The Art of Computer Programming".
Note however that the buddy allocator used by Linux is a little different from the one depicted there.
Buddy allocator is a simple and cost effective memory allocation algorithm that leverages onto a binary tree that represents used or unused split memory blocks: the only notable drawback it has is that it does not completely avoid external fragmentation: although the coalesce of blocks tried when deallocating mitigate this problem a lot , it does not completely address it.
Initialization
In a buddy system, the entire memory space available for allocation is initially split into contiguous blocks; their size is calculated using the following formula:
PAGE_SIZE * 2 <sup>MAX_ORDER - 1</sup>This means that the size of blocks of order 11 (the biggest ones) is 4 KiB * 210 = 4 MiB.
So for example in a system equipped with with 2 GiB of RAM at boot has a little few than 512 order 11 companion buddies:
2 GiB / 4 MiB = 2.048 MiB / 4 MiB = 512they are not actually exactly 512 because of Memory Zones: for example, considering a x86_64 bit system, we have the first 16 MiB reserved to DMA Zone, whereas all the rest is DMA32 Zone.
So the actual number of companion buddies is:
( 2.048MiB - 16 MiB ) / 4 MiB = 2.032 MiB / 4 MiB = 508Memory allocation
After this initial setup, at each page frame allocation request, a set of contiguous blocks of the order as close as possible to the request that can hold the requested size is allocated: the number of blocks is obviously calculated by dividing the requested size by the size of the block; if there's a remainder, an additional block is taken.
It's on the remainder that the buddy algorithm is focused: here it is started a recursive algorithm that splits this last block into two blocks of the lower order - those blocks are said companion buddies.
If the remainder is less than the lowest of the two companion buddies, the algorithm is recursively applied to it, otherwise the lowest companion buddy is allocated and it is calculated the difference from the remainder and the size of the other companion buddy, considering the result as a residual reminder. Then the algorithm is recursively applied to the unallocated companion buddy.
The recursion goes on until either the remainder becomes 0 or the order 0 is reached.
Memory de-allocation
When a process terminates, the blocks that were allocated to it are freed: the algorithm tries to merge a buddy that has become free with its companion buddy - this process is called coalescing. Remember that two blocks are said to be companion buddies if they are the outcome of a previous split of the same direct parent block.
Checking memory blocks availability
As we saw, on Linux system there are 11 orders, so the available blocks size is as depicted by the following table:
You can check the availability of blocks of any orders by inspecting /proc/buddyinfo file:
cat /proc/buddyinfoan example output is as follows:
Node 0, zone DMA 2 1 0 0 2 1 1 0 1 1 3
Node 0, zone DMA32 386 1282 7088 3123 305 36 8 0 0 0 0
Node 0, zone Normal 26930 4168 2670 1796 1021 456 123 11 1 0 0
Node 1, zone Normal 37472 9367 8650 5344 3117 1471 515 147 20 0 0from this output we can guess that:
- this is a x86_64 Kernel - there's no Highmem Zone
- this server has two physical CPUs (Node 0, Node 1)
- memory allocation is quite fragmented - both node 0 and 1 has exhausted< order above 9 (we start counting by 0) - this means that we have no more buddy companions of 2(10-1) * PAGESIZE (512 * 4 Kib = 2 MiB) neither 2(11-1) * PAGESIZE (1024 * 4 Kib = 4 MiB)
Building a solid Linux engineering foundation starts here.Understanding physical memory allocation is vital for students.
However, kernel mechanics are just one technical brick. Real-world infrastructures demand a massive, interconnected skill set.
If you want to bridge OS theory with enterprise automation, jump directly to the Apress Blueprint Box below to discover how to boost and evolve your career using a self-paced learning path.
Memory Fragmentation
It occurs when while deallocating memory it is not possible to coalesce two companion buddies into one of the higher order: since the Linux kernel supports virtual memory management, most of the time physical memory fragmentation is not an issue, but anyway on systems that are up for a very long time it can become very difficult to allocate contiguous physical memory.
Running Out Of Memory
Let see how does memory fragmentation occur in practice: to keep things simple, consider the following example of a very small memory of 32K with a maximum order of 1.
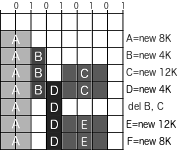
- Process A requests 8K: a block of 8K (order 1) is allocated
- Process B requests 4K: a block of 8K (order 1) is split into two blocks of 4K (order 0) and the lowest companion buddy is allocated to it
- Process C requests 12K: a block of 8K (order 1) is allocated and another one is split into two blocks of 4K (order 0) and the lowest companion buddy is allocated to it
- Process D requests 4K: since there is already a buddy of 4K, companion of the one provided to B, the kernel assigns it to the process
We are getting close to the problem: when deleting B and C, only C can coalesce two companion buddies to recreate the original 8K: B cannot do this since its companion is still used by D. This means that now we have two 8K (order1) and one 4K (order 0) free blocks.
Now suppose that process E is spawn, requesting 12K: it will get one 8K (order 1) block: to keep memory contiguous, the remaining 4K are provided, splitting the last 8K (order 1) block. So now we have two 4K (order 0) blocks.
You may think that you have still other 8K available for other processes, ... but this is not completely true: if process F is spawn, requesting 8K, you get the "cannot allocate memory error" and an errors like the following ones are logged:
May 10 18:03:22 [server] kernel: swapper: page allocation failure. order:1, mode:0x4020
May 10 20:41:16 [server] kernel: [process_e]: page allocation failure. order:1, mode:0xd0despite you actually having 8K of available memory, they are the sum of two buddies of 4K that are not companions - and so they are not next to each other. Some memory allocators handle this exception requesting a pool of smaller blocks whose sum has the same size of the previous request, but if the requestor allocator cannot handle this exception then the application crashes.
The Linux Buddy Allocator
The buddy allocator used by Linux adds several enhancements to the algorithm we've just seen above - it adds the following extensions:
- Per-CPU pageset
- Partitions' buddy allocator
- Group by migration types
The per-CPU pageset is actually a way to reduce lock contention between processors and to optimize single page allocation
Group by migration types is an extension added to limit external memory fragmentation: this is a long-standing problem and several methods (and so several patches) have been submitted trying to deal with it. Some of them, although maybe controversial, have been actually merged.

As for migrations, the use of a virtual address space enable us to easily move data across physical pages: only the value of the direct page table entry should be set to the new page frame number - the virtual address remains the same.
Problems arise when dealing with addresses belonging to the linear mapping area, ... things go really different: the virtual address equals the physical address plus the constant - this means that moving data across physical pages would actually modify the address and so any process that tries to access the old virtual address will fail. This means that migration of these pages should be avoided. This is the underlying reason for grouping by migration type: since managing the migration of both kinds of pages the same way can cause external memory fragmentation, the kernel implements different migration types and group pages on these while defragmenting.
By inspecting /proc/pagetypeinfo we can view the distribution of each migration type:
cat /proc/pagetypeinfoan example output is as follows:
Page block order: 9
Pages per block: 512
Free pages count per migrate type at order 0 1 2 3 4 5 6 7 8 9 10
Node 0, zone DMA, type Unmovable 1 0 0 1 2 1 1 0 1 0 0
Node 0, zone DMA, type Movable 0 0 0 0 0 0 0 0 0 1 3
Node 0, zone DMA, type Reclaimable 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Unmovable 0 0 0 24 5 0 0 1 1 1 0
Node 0, zone DMA32, type Movable 6030 3386 1838 1145 686 337 139 50 19 2 544
Node 0, zone DMA32, type Reclaimable 0 0 1 1 0 1 0 0 0 0 0
Node 0, zone DMA32, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone DMA32, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Unmovable 44 132 87 33 11 2 1 1 1 0 0
Node 0, zone Normal, type Movable 1 1 16 2 2 0 0 0 0 1 0
Node 0, zone Normal, type Reclaimable 0 1 10 2 0 0 0 1 0 0 0
Node 0, zone Normal, type HighAtomic 0 0 0 0 0 0 0 0 0 0 0
Node 0, zone Normal, type Isolate 0 0 0 0 0 0 0 0 0 0 0
Number of blocks type Unmovable Movable Reclaimable HighAtomic Isolate
Node 0, zone DMA 1 7 0 0 0
Node 0, zone DMA32 50 1682 52 0 0
Node 0, zone Normal 83 158 15 0 0
the above report groups pages by region (DMA, DMA32, Normal) and migration type. The available migration types are as follows:
using Movable and Reclaimable pages.
When all of the pages of a given migration type are exhausted, the kernel - so to mitigate fragmentation - steals physical pages from other migration types, preferring pages with the largest block.

Memory reclaiming And Compaction
Memory reclaiming is the process of freeing pages of Reclaimable migration type: it is quick and painless to free them, since their contents can be restored from disk blocks when needed. Each time two contiguous pages of the same order are reclaimed, they are merged into a page of the above order. This process is performed by the kswapd kernel thread.
Memory compaction is a more performance hitting process: it consists of seeking pages of MIGRATE_MOVABLE migration type from the bottom of the considered zone and, at the same time, scanning for free pages from the top of the zone; the process shifts the found pages of MIGRATE_MOVABLE migration type to the top: the straightforward outcome is increasing the number of the free pages on the bottom, and having all of the pages of MIGRATE_MOVABLE migration type on the top. This process, that was previously accomplished by kswapd, since kernel 4.6 is performed by a new dedicated kernel thread: kcompactd.
They can run asynchronous or in direct mode: when the low watermark is hit, they run asynchronously - that means that they are running since the system is anticipating forecast future memory allocation requests. If instead the min watermark is hit, they run in direct mode, ... that in turn means that they are forced to run each time a memory allocation request is made, trying to satisfy it. If the request still fails, the OOM killer is launched and a process gets killed.
These watermarks, expressed as pages, are bound to each memory zone, and are derived from the value of vm.min_free_kbytes using the following formulas:
- watermark[low] = watermark[min] * 5 / 4
- watermark[high] = watermark[min] * 3 / 2
Note that vm.min_free_kbytes is the sum of the mins of all of the zones. We can get the current values of both low and high watermarks for each of the zones as follows:
cat /proc/zoneinfofor example, values for zone DMA32 are:
Node 0, zone DMA32
...
pages free 403938
min 11173
low 13966
high 16759
...
let's compare them to the outcome of the previous formulas:
- watermark[low] = watermark[min] * 5 / 4 = 11173 * 5 / 4 = 13966.25
- watermark[high] = watermark[min] * 3 / 2 = 11173 * 3 / 2 = 16759.5
the previous output shows also the watermark[min] of each zone. Note that it is measured in pages.
We can easily get the sum of watermark[min] of all of the zones:
cat /proc/zoneinfo | grep -A 1 "pages free"the outcome is:
pages free 3977
min 90
--
pages free 403917
min 11173
--
pages free 0
min 0
--
pages free 0
min 0
--
pages free 0
min 0
from the sum, we can guess the value of vm.min_free_kbytes:
(11173 + 90 ) * 4KiB = 45.052 KiB
Are you enjoying these high quality free contents on a blog without annoying banners? I like doing this for free, but I also have costs so, if you like these contents and you want to help keeping this website free as it is now, please put your tip in the cup below:
Even a small contribution is always welcome!
let's check it as follows:
cat /proc/sys/vm/min_free_kbyteson my system the outcome is 45.052.
We can (carefully) play with when we are running out of physical memory: this alters the frequency of when kswapd and kompactd are woken up.
We can go by trials to figure out the proper value by issuing a command like the following one multiple times increasing the value at each run:
sysctl -w vm.min_free_kbytes=101376once we get a suitable value, we must store it into a sysctl config file so to have it automatically set at boot:
echo "vm.min_free_kbytes=101376" >> /etc/sysctl.d/99-buddy-fix.confAs we saw before, memory compaction is a more performance hitting process: besides the watermark[low], there's also a fragmentation specific threshold that should be hit before actually starting a compaction: it is set governed by the vm/extfrag_threshold tunable - memory compaction is triggered when the fragmentation index is less or equal to its value:
cat /proc/sys/vm/extfrag_thresholdon my system the output is
500that by the way is the default value: we can of course adjust it by setting a different value, making it more or less prone to compact memory or direct reclaim to satisfy a high-order allocation.
We can check the fragmentation degree of each order by looking at the /sys/kernel/debug/extfrag/extfrag_index file:
sudo cat /sys/kernel/debug/extfrag/extfrag_indexif you issue this right after the system boot it looks as follows:
Node 0, zone DMA -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000
Node 0, zone DMA32 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000as you can see, it reports the external fragmentation degree grouped by node for each of the orders. The meaning of these values is as follows:
- tending towards 0 imply allocations would fail due to lack of memory
- tending towards 1000 imply failures are due to fragmentation
- -1 implies that the allocation will succeed as long as watermarks are met
Mastering a Custom CA is Just One Brick in the DevSecOps Wall
Successfully mastering page frame distribution, computing zone watermarks, and diagnosing memory fragmentation are outstanding core competencies for any computer science student or systems engineer. Yet, understanding the inner workings of the Linux kernel represents just one single technical brick in the massive wall of modern DevOps and DevSecOps engineering. To transition from academic theory to a successful enterprise career, you must know how to translate host-level mechanics into robust automation architectures, secure development cycles, and production-grade delivery chains without vendor lock-in.
When you look at your future career path, are you confident across the entire enterprise technical stack? Or do you feel you have significant knowledge gaps holding your professional potential back?
My book, "DevSecOps and DevOps for Linux: The Foundations", published by Apress, was specifically designed as a comprehensive, lab-driven blueprint to help both students and early-career professionals systematically fill their technical gaps. Through intensive, hands-on enterprise exercises built entirely on open-source, cloud-agnostic architectures, you will discover how to connect low-level Linux internals with advanced shell scripting, native system packaging, configuration management, and cloud-native GitOps pipelines on enterprise Kubernetes.
Key insights covered in this volume:
- The Holistic Skills Set Brick: Bridge technical engineering with team management frameworks. Master
Scrum,Kanban, andLeanmethodologies to design system architectures aligned with real corporate workflows. - The Shell Scripting & Unix Tools Brick: Build rigorous operational foundations. Master advanced
Bashshell scripting architecture while learning how to combine core Unix tools into robust, repeatable, and enterprise-ready host automations. - The Version Control Engineering Brick: Move past basic commits. Dive deep into
Gitversion control, mastering feature-branch workflows, repository lifecycle management, and complex conflict resolution. - The Data & Core Automation Brick: Build bulletproof data processing setups. Learn advanced
RegEx, how to operate using evergreen tools such asGrep,Sed, andAWK, and how to master structured data parsing (XML,JSON,YAML) usingPythonand tools likexmlstarlet,jq, andyq. - The Modern Python & Automation Brick: Develop a modern Python project using
pyproject.tomlwithpytest-based unit tests, governing the project withGNU Makefor testing, building, and digitally signingRPMpackages. The project is presented in an evolving fashion, showing how features are added step by step, highlighting how a properly structured Python project can be improved and evolved with minimal or no rework at all. - The Linux OS Hardening & PKI Brick: Learn the real mechanics of security. Implement
X.509/PKIarchitectures,TLSconfigurations, andGPGencryption and signing, while mastering low-level kernel defenses likeSELinuxandLinux Capabilities. - The Compliance Check and Shift-Left Security Brick: Learn how to leverage the
pre-commitframework to automate compliance checks withPylintandFlake8, and perform security scans withBanditandSafety, extending the security audit to the full software supply chain. - The Application Integration Brick: Master the foundational protocols used to securely interconnect enterprise microservices, including
HTTP,REST,OpenAPI,SOAP, andLDAP/LDAPS. - The Infrastructure Delivery Brick: Put theory into practice with vertical, real-world labs. Move from basic scripts to engineering
Ansiblearchitectures, rootlessPodmansetups, image creation viaBuildah, and completePulp3deployments usingDocker Compose. - The Enterprise GitOps Pipeline Brick: Tie everything together by automating your software supply chain. Build complete continuous deployment workflows using
Gitea CIpipelines hosted natively onKubernetes(RKE2).
