Kubernetes is certainly the most popular and probably the best solution for orchestrating containerized workloads, but maintaining its vanilla distribution is certainly a challenge, so you must carefully guess pros and cons in terms of maintenance costs and operational risks.
A very cost effective and interesting alternative to running the vanilla Kubernetes is the "Rancher Kubernetes Engine 2" (RKE2), a certified Kubernetes distribution focused on security to adhere to the U.S. government’s compliance requirement. RKE2, besides providing a reliable Kubernetes distribution, smoothly integrates with Rancher.
In the "RKE2 Tutorial - RKE2 Howto On Oracle Linux 9" post we see it in action, installing a highly available multi-master Kubernetes cluster, exposing the default ingress controller using MetalLB for providing Load Balancing services.
Acquainting To RKE
Before starting, we must at least learn the bare minimum about the Rancher Kubernetes Engine (RKE) projects.
RKE
First released in January 2018, Rancher Kubernetes Engine (RKE) is a CNCF-certified Kubernetes distribution that runs entirely within Docker containers: this design makes it independent by the underlying operating system and platform - the only environment requisite is supporting Docker.
It has been developed to provide a simplified and easily automated way for deploying Kubernetes and in its lifecycle it was released more than 600 times.
RKE2
RKE2, sometimes called RKE Government, is Rancher's next-generation Kubernetes distribution: it is a certified Kubernetes distribution focused on security to adhere to the U.S. government’s compliance requirements.
To meet these strict requirements, RKE2:
- Provides defaults and configuration options that allow to set up CIS Kubernetes Benchmark v1.6 or v1.23 compliant clusters
- Enables FIPS 140-2 compliance
- Regularly scans for CVEs are performed on the RKE2 components
RKE2 uses "containerd" as the embedded container runtime, launching the control plane components as static pods, managed by the kubelet.
As of Rancher v2.6+, it is possible to deploy RKE2 clusters using the Rancher’s Web UI.
The Lab
In this post we will see RKE2 in action, deploying an High Available Kubernetes cluster with the following topology:
Kubernetes Master Nodes (RKE2 Servers)
- kubea-ca-up1a001.p1.carcano.corp
- kubea-ca-up1b002.p1.carcano.corp
- kubea-ca-up1c003.p1.carcano.corp
Kubernetes Worker Nodes (RKE2 agents)
- kubew-ca-up1a004.p1.carcano.corp
- kubew-ca-up1b005.p1.carcano.corp
- kubew-ca-up1c006.p1.carcano.corp
These hosts must be scattered on three different availability zones - in my naming scheme the letter after the "p1" environment/security tier in the hostname is a hint to know to which availability zone the host belongs to (a, b or c).
In order to be able to set up both Kubernetes and RKE2 are configured high available, it is also mandatory to have a load balancer in front of them: you can use your preferred one, until it meets the following requisites:
- provide a load balancing endpoint for the RKE2 supervisor service instances - protocol TCP, port 9345
- provide a load balancing endpoint for the Kubernetes master service instances - protocol TCP, port 6443
- the load balancer itself must be high available
As for the TLS mode, both RKE2 and Kubernetes support either TLS termination or TLS pass-through. Anyway, mind that configuring TLS termination on these endpoints requires additional setup and maintenance effort and has a negative impact on performance without bringing any real benefit.
Prerequisites
As every software, RKE2 has some prerequisites that it is mandatory to address before going on. Mind that this post is based on Oracle Linux 9.3, so there may be a few little differences if you are using another platform.
The minimal hardware requirements are:
- RKE server (the Kubernetes API nodes): CPU: 2 (recommended 4), RAM: 4 GB minimum, at least 8GB recommended
- RKE agent (the Kubernetes worker nodes): CPU: 2, RAM: 4GB - this is the bare minimum, the actual sizing depends on the workload you want to schedule on them
In general, the best practice is to have the "/var" filesystem backed up by a dedicated filesystem mounted on the "/var" mount point - even better is having also "/var/lib" on its own filesystem. The minimum free space required on the filesystem where the running container overlays are running is 16GiB.
Before installing or upgrading RKE2, it is always best to read the official known issues page to be aware of the requirements.
Remove Podman And Buildah
Since (sadly) Podman is not supported, if it is already installed on your system, it must uninstalled as follows:
sudo dnf remove -y podman buildahUpdate The System
As by best practices, the very first requisite is to update the platform:
sudo dnf update -yAdd Entries To The Hosts file
I know it may sound odd, but one of the gold rules for achieving a very reliable cluster is to add entries to the "/etc/hosts" file with every host belonging to the cluster - this spares from intermittent latency related problems that may arise with DNS resolution.
So, for example:
10.208.23.16 kube-p1-0.p1.carcano.corp
10.211.55.221 kubea-ca-up1a001.p1.carcano.corp kubea-ca-up1a001
10.211.55.220 kubea-ca-up1b002.p1.carcano.corp kubea-ca-up1b002
10.211.55.219 kubea-ca-up1c003.p1.carcano.corp kubea-ca-up1c003
10.211.55.228 kubew-ca-up1a004.p1.carcano.corp kubew-ca-up1a004
10.211.55.217 kubew-ca-up1b005.p1.carcano.corp kubew-ca-up1b005
If you prefer a more "resilient" and dynamic way to cope with that, you may consider installing a caching DNS resolver, such as "systemd-resolved" , "dnsmasq" , or "unbound".
Stop And Disable Firewalld
Firewalld is known to conflict with RKE2's default Canal (Calico + Flannel) networking stack.
For this reason it is mandatory to disable it as follows:
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo systemctl mask firewalldPrevent Network-Manager From Managing Canal And Flannel Interfaces
NetworkManager can interfere with the CNI’s ability to route correctly: for this reason it is necessary to configure NetworkManager to ignore Calico/Flannel related network interfaces.
To avoid this, just create the "/etc/NetworkManager/conf.d/rke2-canal.conf" file with the following contents:
[keyfile]
unmanaged-devices=interface-name:cali*;interface-name:flannel*Disable Nm-cloud-Setup
On some systems, such as Oracle Linux 8.4, NetwokManager includes two extra services: "nm-cloud-setup.service" and "nm-cloud-setup.timer".
Since these services add a routing table that interfere with the CNI plugin's configuration, it is mandatory to disable them as follows:
sudo systemcl disable nm-cloud-setup.service
sudo systemcl disable nm-cloud-setup.service
sudo systemcl mask nm-cloud-setup.timer
sudo systemcl mask nm-cloud-setup.timerReboot The System
Since we have not done this after the upgrade yet, we must now restart the system so to have all the changes we did so far applied::
sudo shutdown -r nowSetup A PassThrough Load Balancer
As we said, to run an high-available instance, it is mandatory to have both the RKE2 supervisor and the Kubernetes master services behind a load balancer.
For your convenience, I'm providing a few snippets you can use as a hint to configure HAProxy.
The provided snippets are very trivial and are just given as hints - If you want to learn HAProxy the proper way, you may find interesting my posts "High Available HAProxy Tutorial With Keepalived" and "HAProxy Tutorial - A Clean And Tidy Configuration Structure".
RKE2 Supervisor Service
RKE2 supervisor service binds to port 9345 (protocol TCP).
The below snippet configures the listener on the load balancer:
listen 9345-tcps.1
mode tcp
description RKE2 supervisor
bind 10.208.23.16:9345
option tcplog
default_backend kube-p1-0.p1.carcano.corp:9345whereas the below one sets up the backend pool:
backend kube-p1-0.p1.carcano.corp:9345
mode tcp
description RKE2 supervisor on cluster kube-p1-0.p1.carcano.corp
option tcp-check
balance roundrobin
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server kubea-ca-up1a001 10.211.55.221:9345 check
server kubea-ca-up1b002 10.211.55.220:9345 check
server kubea-ca-up1c003 10.211.55.219:9345 checkAt the time of writing this post, the RKE2 agent's component "rke2-agent-load-balancer" does not set the Server Name Identifier (SNI) when calling the supervisor service. You must be wary of this, since it prevents you from sharing the IP on the load balancer with other services on the same port, leading to the requirement of having a dedicated IP address.
The symptom of this problem can be detected by checking the rke2-agent's logs right after the startup of the service:
level=info msg="Starting rke2 agent v1.31.2+rke2r1 (dc4219f5755bb1deb91619550b3565892b57ecdb)"
level=info msg="Adding server to load balancer rke2-agent-load-balancer: kube-p1-0.p1.carcano.corp:9345"
level=info msg="Running load balancer rke2-agent-load-balancer 127.0.0.1:6444 -> [kube-p1-0.p1.carcano.corp:9345] [default: kube-p1-0.p1.carcano.corp:9345]"Kubernetes Master Service
Kubernetes Master binds to port 6443 (protocol TCP).
The below snippet configures the listener on the load balancer:
listen 6443-tcps.1
mode tcp
description Kubernetes master
bind 10.208.23.16:6443
option tcplog
default_backend kube-p1-0.p1.carcano.corp:6443whereas the below one sets up the backend pool:
backend kube-p1-0.p1.carcano.corp:6443
mode tcp
description Kubernets master on cluster kube-p1-0.p1.carcano.corp
option tcp-check
balance roundrobin
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server kubea-ca-up1a001 10.211.55.221:6443 check
server kubea-ca-up1b002 10.211.55.220:6443 check
server kubea-ca-up1c003 10.211.55.219:6443 checkOf course, for the sake of keeping things clean and tidy, you must use the same IP address you used for the RKE2 supervisor service.
Install RKE2
We are ready to install RKE2.
Configure The DNF Repositories
The first decision to take is which version you want to install - the full release list is available at https://github.com/rancher/rke2-packaging/releases.
This task must obviously be done on every node: once chosen the release, set which "RKE2_MINOR" environment variable with the RKE2 version you want to install.
export RKE2_MINOR=31
We must also set the "LINUX_MAJOR" and "ARCH" environment variables to reflect the current Oracle Linux version and architecture:
export LINUX_MAJOR=9
export ARCH=aarch64we can now create the "/etc/yum.repos.d/rancher-rke2-stable.repo" DNF repositories configuration file as follows:
sudo tee /etc/yum.repos.d/rancher-rke2-stable.repo <<EOF
[rancher-rke2-common-stable]
name=Rancher RKE2 Common Stable
baseurl=https://rpm.rancher.io/rke2/stable/common/centos/${LINUX_MAJOR}/noarch
enabled=1
gpgcheck=1
gpgkey=https://rpm.rancher.io/public.key
[rancher-rke2-1-${RKE2_MINOR}-stable]
name=Rancher RKE2 1.${RKE2_MINOR} Stable
baseurl=https://rpm.rancher.io/rke2/stable/1.${RKE2_MINOR}/centos/${LINUX_MAJOR}/${ARCH}
enabled=1
gpgcheck=1
gpgkey=https://rpm.rancher.io/public.key
EOFthe "stable" repositories provide the RKE2 stable version: on production systems, you must alway install packages from the "stable" repositories.
For the sake of completeness, you can configure also the "latest" repositories - just create the "/etc/yum.repos.d/rancher-rke2-latest.repo" DNF repositories configuration file as follows:
sudo tee /etc/yum.repos.d/rancher-rke2-latest.repo <<EOF
[rancher-rke2-common-latest]
name=Rancher RKE2 Common Latest
baseurl=https://rpm.rancher.io/rke2/latest/common/centos/${LINUX_MAJOR}/noarch
enabled=0
gpgcheck=1
gpgkey=https://rpm.rancher.io/public.key
[rancher-rke2-1-${RKE2_MINOR}-latest]
name=Rancher RKE2 1.${RKE2_MINOR} Latest
baseurl=https://rpm.rancher.io/rke2/latest/1.${RKE2_MINOR}/centos/${LINUX_MAJOR}/${ARCH}
enabled=0
gpgcheck=1
gpgkey=https://rpm.rancher.io/public.key
EOFInstall The RKE2 Server Packages
On the hosts designated to be the Kubernetes master nodes, install the "rke2-server" package as follows:
sudo dnf -y install rke2-serverRKE2 command line utilities are installed beneath the "/var/lib/rancher/rke2" directory: in order to be able to run tools such as the "kubectl" command line utility without providing the full path, create the "/etc/profile.d/rke2.sh" file with the following contents:
export PATH=${PATH}:/var/lib/rancher/rke2/bin
export KUBECONFIG=/etc/rancher/rke2/rke2.yamlas you see, it also exports the "KUBECONFIG" variable with the path to the Kubernetes' client configuration file used by "kubectl".
Install The RKE2 Agent Packages
On the hosts designated to be the Kubernetes worker nodes, install the "rke2-agent" package as follows:
sudo dnf -y install rke2-agentConfigure RKE2 And Deploy Kubernetes
We are now ready for configuring RKE2: once the configuration file is set, it is enough to start the RKE2 service related to the host type (server or agent) and wait for it to deploy Kubernetes.
Setup Kubernetes Master Nodes
RKE2 server nodes are the nodes where RKE2 deploys and maintains the Kubernetes master instances.
1st Kubernetes Master Node

Are you enjoying these high quality free contents on a blog without annoying banners? I like doing this for free, but I also have costs so, if you like these contents and you want to help keeping this website free as it is now, please put your tip in the cup below:
Even a small contribution is always welcome!
On the first RKE2 server host - "kubea-ca-up1a001.p1.carcano.corp" in this example, configure the "/etc/rancher/rke2/config.yaml" file as follows:
write-kubeconfig-mode: "0640"
token: kube-p1-0-aG0Wg.0dT3.Hd
tls-san:
- "kube-p1-0.p1.carcano.corp"
- "kubea-ca-up1a001.p1.carcano.corp"
- "kubea-ca-up1a001"
- "10.211.55.221"
cluster-cidr: 192.168.0.0/16
service-cidr: 172.16.0.0/12
cluster-dns: 172.16.0.10
etcd-arg: "--quota-backend-bytes 2048000000"
etcd-snapshot-schedule-cron: "0 3 * * *"
etcd-snapshot-retention: 10
etcd-expose-metrics: true
kube-apiserver-arg:
- "--default-not-ready-toleration-seconds=30"
- "--default-unreachable-toleration-seconds=30"
kube-scheduler-arg:
- "bind-address=0.0.0.0"
kube-controller-manager-arg:
- "bind-address=0.0.0.0"
- "--node-monitor-period=4s"
kubelet-arg:
- "--node-status-update-frequency=4s"
- "--max-pods=100"
kube-proxy-arg:
- metrics-bind-address=0.0.0.0:10249
node-taint:
- "CriticalAddonsOnly=true:NoExecute"the above directives instruct RKE2 to perform the following actions:
- create the "/etc/rancher/rke2/rke2.yaml" with read access to the owning group (line 1) - mind that yourself if there are security impacts on this breaking your security compliance, then you must adjust these setting accordingly to comply to it
- set the token used for authenticating other RKE2 instances (no matter if they are server or agents) joining the cluster (line 2)
- provide a list of TLS Subject Alternative Names (SAN) to be added to the X.509 certificates generated (lines 3-7) - as you see, besides the node's FQDN, hostname and IP address it contains also the FQDN of the load balanced endpoint in front of the RKE2 servers and Kubernetes masters services ("kube-p1-0.p1.carcano.corp")
- provide the subnet to be used for the POD's subnets (line 8)
- provide the subnet to be used for the service subnet - the one for the services reachable only from the containers running in Kubernetes (line 9)
- provide the IP address of the coreDNS' service on the service network (line 10) - it must of course belong to the service subnet
- set the "etcd" quota to 2GB (line 11)
- scheduled interval for taking "etcd" snapshot ("etcd" backups) (line 12)
- number of "etcd" snapshot to keep (line 13)
- set up etcd to expose Prometheus metrics (line 14) - it is a mandatory requirement for running "kube-prometheus-stack"
- set some "api-server" settings related to the availability (lines 15-17) - the full set of options is available at https://kubernetes.io/docs/reference/command-line-tools-reference/kube-apiserver/.
- configure the "scheduler" to bind to every network interface (lines 18-19 - it is a mandatory requirement for running "kube-prometheus-stack") - the full set of options is available at https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/.
- configure the "controller-manager" to bind to every network interface (it is a mandatory requirement for running "kube-prometheus-stack") and to monitor nodes every 4 seconds (lines 20-22) - the full set of options is available at https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/.
- set some "kubelet" settings related to the availability and capacity (lines 23-25) - the full set of options is available at https://kubernetes.io/docs/reference/command-line-tools-reference/kubelet/.
- configure the "kube-proxy" to bind the metrics collecting endpoint to every network interface (lines 26-27 - it is a mandatory requirement for running "kube-prometheus-stack") - the full set of options is available at https://kubernetes.io/docs/reference/command-line-tools-reference/kube-proxy/.
- taint the node (lines 28-29) - in Kubernetes terms, it prevents workload to be scheduled on this node, so to have it dedicated only to the Kubernetes master processes.
Once done, start the RKE2 server process and enable it at boot as follows:
sudo systemctl enable --now rke2-serverPlease mind that it is normal that it takes some time before returning to the shell.
Once it returns the control to the shell, to avoid running "kubectl" as a privileged user, we can create the "kubernetes" group:
sudo groupadd kubernetesand assign it to the "/etc/rancher/rke2/rke2.yaml" file:
sudo chgrp kubernetes /etc/rancher/rke2/rke2.yamlthis way, the members of the "kubernetes" group have read access to the kubectl's configuration file.
Let's now add the current user to the "kubernetes" group (in this example I'm using the "vagrant" user:
sudo usermod -a -G kubernetes vagrantdo the same for every user you want to grant the rights to access this Kubernetes instance.
Once done, disconnect and reconnect the current user to have the group change applied to the user session.
Once reconnected, type the following statement:
kubectl get all --all-namespacesAs you see the main pods of the Kubernetes master have been deployed, and it is waiting before deploying the rest:
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system pod/etcd-kubea-ca-up1a001.p1.carcano.corp 1/1 Running 0 41s
kube-system pod/kube-apiserver-kubea-ca-up1a001.p1.carcano.corp 1/1 Running 0 45s
kube-system pod/kube-proxy-kubea-ca-up1a001.p1.carcano.corp 1/1 Running 0 36s
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/kubernetes ClusterIP 172.16.0.1 443/TCP 47s
NAMESPACE NAME COMPLETIONS DURATION AGE
kube-system job.batch/helm-install-rke2-canal 0/1 42s
kube-system job.batch/helm-install-rke2-coredns 0/1 42s
kube-system job.batch/helm-install-rke2-ingress-nginx 0/1 42s
kube-system job.batch/helm-install-rke2-metrics-server 0/1 42s
kube-system job.batch/helm-install-rke2-snapshot-controller 0/1 40s
kube-system job.batch/helm-install-rke2-snapshot-controller-crd 0/1 40s
kube-system job.batch/helm-install-rke2-snapshot-validation-webhook 0/1 39sWe can now move forward and start configuring and deploying the second master node.
2nd Kubernetes Master Node
On the first RKE2 server host - "kubea-ca-up1b002.p1.carcano.corp" in this example, configure the "/etc/rancher/rke2/config.yaml" file as follows:
write-kubeconfig-mode: "0640"
server: https://kube-p1-0.p1.carcano.corp:9345
token: kube-p1-0-aG0Wg.0dT3.Hd
tls-san:
- "kube-p1-0.p1.carcano.corp"
- "kubea-ca-up1b002.p1.carcano.corp"
- "kubea-ca-up1b002"
- "10.211.55.220"
cluster-cidr: 192.168.0.0/16
service-cidr: 172.16.0.0/12
cluster-dns: 172.16.0.10
etcd-arg: "--quota-backend-bytes 2048000000"
etcd-snapshot-schedule-cron: "0 3 * * *"
etcd-snapshot-retention: 10
etcd-expose-metrics: true
kube-apiserver-arg:
- "--default-not-ready-toleration-seconds=30"
- "--default-unreachable-toleration-seconds=30"
kube-scheduler-arg:
- "bind-address=0.0.0.0"
kube-controller-manager-arg:
- "bind-address=0.0.0.0"
- "--node-monitor-period=4s"
kubelet-arg:
- "--node-status-update-frequency=4s"
- "--max-pods=100"
kube-proxy-arg:
- metrics-bind-address=0.0.0.0:10249
node-taint:
- "CriticalAddonsOnly=true:NoExecute"As you see, it is exactly the same content we used while configuring the first master node, except the TLS SANS, which must reflect this node's FQDN, hostname and IP address. In addition to that, it is obvious we must also provide the URL of the server to join - "https://kube-p1-0.p1.carcano.corp:9345" (the URL of the RKE2 server on the load balancer).
Once done, start the RKE2 server process and enable it at boot as follows:
sudo systemctl enable --now rke2-serverAgain, mind that it is normal that it takes some time before returning to the shell.
We must of course do the same trick we did on the first Kubernetes master server, to avoid running "kubectl" as a privileged user:
sudo groupadd kubernetes
sudo chgrp kubernetes /etc/rancher/rke2/rke2.yaml
sudo usermod -a -G kubernetes vagrantWe can now move forward and start configuring and deploying the third and last master node.
3rd Kubernetes Master Node
On the first RKE2 server host - "kubea-ca-up1c003.p1.carcano.corp" in this example, configure the "/etc/rancher/rke2/config.yaml" file as follows:
write-kubeconfig-mode: "0640"
server: https://kube-p1-0.p1.carcano.corp:9345
token: kube-p1-0-aG0Wg.0dT3.Hd
tls-san:
- "kube-p1-0.p1.carcano.corp"
- "kubea-ca-up1c003.p1.carcano.corp"
- "kubea-ca-up1c003"
- "10.211.55.219"
cluster-cidr: 192.168.0.0/16
service-cidr: 172.16.0.0/12
cluster-dns: 172.16.0.10
etcd-arg: "--quota-backend-bytes 2048000000"
etcd-snapshot-schedule-cron: "0 3 * * *"
etcd-snapshot-retention: 10
etcd-expose-metrics: true
kube-apiserver-arg:
- "--default-not-ready-toleration-seconds=30"
- "--default-unreachable-toleration-seconds=30"
kube-scheduler-arg:
- "bind-address=0.0.0.0"
kube-controller-manager-arg:
- "bind-address=0.0.0.0"
- "--node-monitor-period=4s"
kubelet-arg:
- "--node-status-update-frequency=4s"
- "--max-pods=100"
kube-proxy-arg:
- metrics-bind-address=0.0.0.0:10249
node-taint:
- "CriticalAddonsOnly=true:NoExecute"As you see, it is exactly the same content we used while configuring the second master node, except the TLS SANS, which must reflect this node's FQDN, hostname and IP address.
Once done, start the RKE2 server process and enable it at boot as follows:
sudo systemctl enable --now rke2-serverAgain, mind that it is normal that it takes some time before returning to the shell.
We must of course do the same trick we did on the first Kubernetes master server, to avoid running "kubectl" as a privileged user:
sudo groupadd kubernetes
sudo chgrp kubernetes /etc/rancher/rke2/rke2.yaml
sudo usermod -a -G kubernetes vagrantWe can now move forward and start configuring all the worker nodes.
Setup Kubernetes Worker Nodes
On every RKE2 agent host configure the "/etc/rancher/rke2/config.yaml" file as follows:
server: https://kube-p1-0.p1.carcano.corp:9345
token: kube-p1-0-aG0Wg.0dT3.Hd
kube-proxy-arg:
- metrics-bind-address=0.0.0.0:10249
as you see this is a very small subset of the settings we already used for the master nodes, providing only the URL of the RKE2 server to join, the access token and configure the "kube-proxy" to bind the metrics collecting endpoint to every network interface (a mandatory requirement for running "kube-prometheus-stack").
Once done, start the RKE2 agent process and enable it at boot as follows:
sudo systemctl enable --now rke2-agentAgain, mind that it is normal that it takes some time before returning to the shell.
When the control is returned to the shell, you can have a look to how he deployment process is evolving by typing:
kubectl get all --all-namespacesIf everything is properly working, you must see everything slowly starting and the number of pending tasks reducing.
If instead after some time you get a output like the below one:
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system pod/etcd-kubea-ca-up1a001.p1.carcano.corp 1/1 Running 0 28m
kube-system pod/etcd-kubea-ca-up1b002.p1.carcano.corp 1/1 Running 0 26m
kube-system pod/etcd-kubea-ca-up1c003.p1.carcano.corp 1/1 Running 0 24m
kube-system pod/kube-apiserver-kubea-ca-up1a001.p1.carcano.corp 1/1 Running 0 28m
kube-system pod/kube-apiserver-kubea-ca-up1b002.p1.carcano.corp 1/1 Running 0 26m
kube-system pod/kube-apiserver-kubea-ca-up1c003.p1.carcano.corp 1/1 Running 0 24m
kube-system pod/kube-proxy-kubea-ca-up1a001.p1.carcano.corp 1/1 Running 0 28m
kube-system pod/kube-proxy-kubea-ca-up1b002.p1.carcano.corp 1/1 Running 0 26m
kube-system pod/kube-proxy-kubea-ca-up1c003.p1.carcano.corp 1/1 Running 0 24m
kube-system pod/kube-proxy-kubew-ca-up1a004.p1.carcano.corp 1/1 Running 0 21m
kube-system pod/kube-proxy-kubew-ca-up1b005.p1.carcano.corp 1/1 Running 0 17m
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default service/kubernetes ClusterIP 172.16.0.1 443/TCP 28m
NAMESPACE NAME COMPLETIONS DURATION AGE
kube-system job.batch/helm-install-rke2-canal 0/1 28m
kube-system job.batch/helm-install-rke2-coredns 0/1 28m
kube-system job.batch/helm-install-rke2-ingress-nginx 0/1 28m
kube-system job.batch/helm-install-rke2-metrics-server 0/1 28m
kube-system job.batch/helm-install-rke2-snapshot-controller 0/1 28m
kube-system job.batch/helm-install-rke2-snapshot-controller-crd 0/1 28m
kube-system job.batch/helm-install-rke2-snapshot-validation-webhook 0/1 28mthen it is very likely that your nodes are below the minimum CPU, RAM or disk space requirements. Investigate it and fix it, until the deployment completes.
Register The RKE2 Cluster In Rancher
If you have a running Rancher installation, this is the right moment for registering this RKE2 cluster on it: by doing so you will be able to do all the next tasks from the Rancher Web UI.
Registering an RKE2 cluster is really a trivial task - just click on the "Manage Clusters" button (the one with the farm), then expand the "Clusters" group - this will list the available clusters.
Click on the "Import Existing".
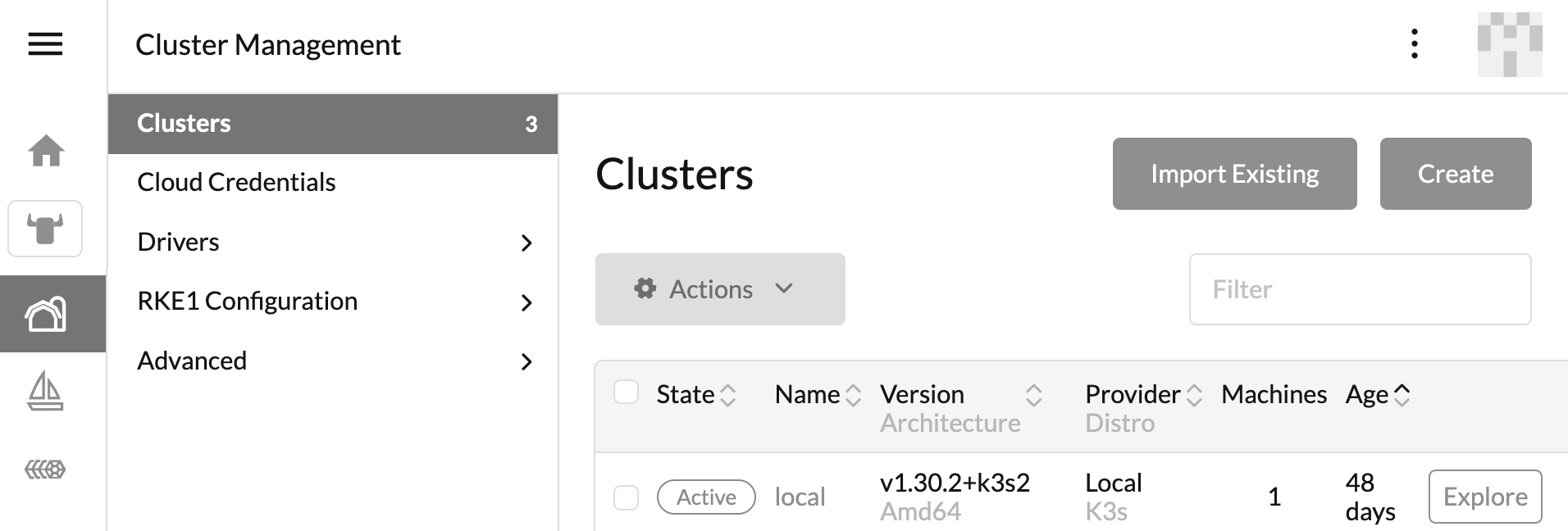
then select the box for importing an RKE2 cluster.
Once done, it will display a page with the statement to run on the RKE2 cluster for deploying the components necessary to register the Kubernetes cluster in Rancher - for example:
kubectl apply -f https://rancher-p1-0.p1.carcano.corp/v3/import/1afresr91wdr62hjqgwvtt45csb1mrr8mcetdkm1thcg4bqw7r4hrw_c-m-tajgk6wq.yamlrun the statement on any of the RKE2 supervisor nodes.
You can monitor the deployment's status by typing:
kubectl -n cattle-system get allthe outcome must look like as follows:
NAME READY STATUS RESTARTS AGE
pod/cattle-cluster-agent-c855dd4df-chml5 1/1 Running 0 2m
pod/cattle-cluster-agent-c855dd4df-kq7lc 1/1 Running 1 (6d17h ago) 2m
pod/rancher-webhook-5c76f64665-sdhdr 1/1 Running 0 2m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/cattle-cluster-agent ClusterIP 172.17.143.26 <none> 80/TCP,443/TCP 2m
service/rancher-webhook ClusterIP 172.30.3.47 <none> 443/TCP 2m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/cattle-cluster-agent 2/2 2 2 2m
deployment.apps/rancher-webhook 1/1 1 1 2m
NAME DESIRED CURRENT READY AGE
replicaset.apps/cattle-cluster-agent-6c75c59477 0 0 0 2m
replicaset.apps/cattle-cluster-agent-c855dd4df 2 2 2 2m
replicaset.apps/rancher-webhook-5c76f64665 1 1 1 2mConfigure Local Registries
One of the very first thing to set up is linking local registries. Their purpose is twofold:
- they speed up deployments, since images must not be downloaded each time from the Internet - this mitigates the impact of pull throttling implemented by public registries such as "docker.io"
- can be used as a repository to store your own container images
As an example, create the "/etc/rancher/rke2/registries.yaml" with the following contents:
mirrors:
docker.io:
endpoint:
- "registry-ca-up1-0.p1.carcano.corp"
gcr.io:
endpoint:
- "registry-ca-up1-0.p1.carcano.corp"
carcano.corp:
endpoint:
- "registry-ca-up1-0.p1.carcano.corp"
configs:
"registry-ca-up1-0.p1.carcano.corp":
auth:
username: docker-svc-p1
password: aG0.dPa66-w0rd
tls:
insecure_skip_verify: truethis manifest declares the endpoint "registry-ca-up1-0.p1.carcano.corp" as:
- a mirror of the public container registries "docker.io" and of "gcr.io"
- a mirror of the private registry "carcano.corp"
- provides the credentials necessry for authenticating to the endpoint
Once created the file, it is necessary to restart the RKE2 service - on a worker node, run:
sudo systemctl restart rke2-agenton a master node, run:
sudo systemctl restart rke2-serverInstall Helm
We must now install Helm on the RKE2 server nodes.
Since Helm has a module dependency on Git, it is best to install Git too as follows:
sudo dnf install -y gitThen download the Helm installer script:
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
chmod 700 get_helm.shand finally install it:
sudo ./get_helm.shsince we do not need the installer any longer, let's remove it:
rm -f get_helm.shPost Installation Steps
We must now deploy some additional components that are nearly mandatory on every production-grade Kubernetes cluster.
Deploy MetalLB
The very first component is MetalLB: if you have Rancher, add the "metallb" Helm repo to the list of repositories available to this Kubernetes cluster and deploy it as an application.
If you don't have Rancher instead proceed as follows:
On every RKE2 server nodes, add the "metallb" Helm repo:
helm repo add metallb https://metallb.github.io/metallbthen, only on one of the RKE2 server nodes, run the below statement to deploy "metallb" in the "metallb-system" namespace:
helm install --create-namespace --namespace metallb-system metallb metallb/metallb
once done, you can have a look to the deployment by typing:
kubectl get pods -n metallb-systemthe output must look like as follows:
NAME READY STATUS RESTARTS AGE
metallb-controller-76bf5df6db-67bdf 1/1 Running 0 51s
metallb-speaker-22jft 4/4 Running 0 51s
metallb-speaker-lwft6 4/4 Running 0 51sConfigure The Ingress Controller
We must then complete the configuration of the ingress controller.
As the first thing, import the X.509 certificate that will be used as the default one - if your security policy permits it, a wildcard certificate here can save you a lot of operational and maintenance work, otherwise deploy and setup cert-manager and have it managed by it (providing the details is out of the scope of this post).
In this example, we are loading the wildcard certificate from the "carcano.corp.crt" file and the key from the "carcano.corp.key" and putting them inside the tls secret called "carcano.corp-wildcard-cert" in the "kube-system" namespace
kubectl create secret tls carcano.corp-wildcard-cert \
--namespace kube-system --cert carcano.corp.crt \
--key carcano.corp.keyRKE2 manages the additional settings using add-ons - you can list the currently available ones by typing:
kubectl -n kube-system get addons -o custom-columns=HELM_CHART:.metadata.name,SOURCE:.spec.sourcethe outcome must look like as follows:
HELM_CHART SOURCE
rke2-canal /var/lib/rancher/rke2/server/manifests/rke2-canal.yaml
rke2-coredns /var/lib/rancher/rke2/server/manifests/rke2-coredns.yaml
rke2-ingress-nginx /var/lib/rancher/rke2/server/manifests/rke2-ingress-nginx.yaml
rke2-metrics-server /var/lib/rancher/rke2/server/manifests/rke2-metrics-server.yaml
rke2-snapshot-controller /var/lib/rancher/rke2/server/manifests/rke2-snapshot-controller.yaml
rke2-snapshot-controller-crd /var/lib/rancher/rke2/server/manifests/rke2-snapshot-controller-crd.yaml
rke2-snapshot-validation-webhook /var/lib/rancher/rke2/server/manifests/rke2-snapshot-validation-webhook.yamlThe above output revealed to us the directory path where RKE2 looks for add-ons manifests: as you see, they are stored in the "/var/lib/rancher/rke2/server/manifests".
We can create an "HelmChartConfig" document with the overrides necessary to complete the ingress controller's configuration.
On every RKE2 server node, create the "/var/lib/rancher/rke2/server/manifests/rke2-ingress-nginx-config.yaml" file with the following contents:
apiVersion: helm.cattle.io/v1
kind: HelmChartConfig
metadata:
name: rke2-ingress-nginx
namespace: kube-system
spec:
valuesContent: |-
controller:
config:
use-forwarded-headers: "true"
enable-real-ip: "true"
publishService:
enabled: true
extraArgs:
default-ssl-certificate: "kube-system/carcano.corp-wildcard-cert"
service:
enabled: true
type: LoadBalancer
external:
enabled: true
externalTrafficPolicy: Local
annotations:
metallb.universe.tf/loadBalancerIPs: 10.211.55.10As you see, the manifest:
- provides the name of the tls secret to use as the default SSL certificate
- enable a LoadBalancer service with IP 10.211.55.10 and exposes the ingress controller with it
To have RKE2 server apply this new manifest, just restart the RKE2 service - one RKE2 server node should be enough:
sudo systemctl restart rke2-server.servicewhen the control returns to the shell, run the following statement:
kubectl -n kube-system get HelmChartConfigthe outcome must be as follows:
NAME AGE
rke2-ingress-nginx 3m43sshowing that the new "HelmChartConfig" we have just configured has actually been loaded.
The last check is ensuring the load balancer has actually been created:
kubectl -n kube-system get svc rke2-ingress-nginx-controlleras you see, the "EXTERNAL-IP" is still in pending state:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rke2-ingress-nginx-controller LoadBalancer 172.25.91.249 <pending> 80:31743/TCP,443:30488/TCP 2m35sThis is because, although we configured in the manifest the IP we want to assign the LoadBalancer, MetalLB has not yet been configured for managing it.
Create the "~/ingress-pool.yaml" file with the following contents:
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: ingress-pool
namespace: metallb-system
spec:
addresses:
- 10.211.55.10/32as you see, it defines the "ingress-pool" IPAddressPool with IP "10.211.55.10".
Apply it as follows:
kubectl apply -f ~/ingress-pool.yamlnow create the "~/advertisement.yaml" file with the following contents:
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: main-advertisement
namespace: metallb-system
spec:
ipAddressPools:
- ingress-poolit defines the "main-advertisement" L2Advertisement to advertise the "ingress-pool" we just created.
Apply it as follows:
kubectl apply -f ~/advertisement.yamlthis time, if we check the ingress controller's LoadBalancer:
kubectl -n kube-system get svc rke2-ingress-nginx-controllerthe outcome is:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rke2-ingress-nginx-controller LoadBalancer 172.25.91.249 10.211.55.10 80:31743/TCP,443:30488/TCP 7m10sso MetalLB has successfully assigned and set up the requested IP.
Deploy a CSI Controller
Kubernetes cannot manage storage provisioning by itself: despite it enables you to configure Persistent Volumes, the backing store must be pre-provisioned. In a fast paced, scalable and resilient environment this can be a limit.
Luckily, Kubernetes provides a standard interface for dynamically provisioning the storage on the fly, also capable of deleting the contents as necessary when the provisioned resource is no longer necessary.
This interface, called Container Storage Interface (CSI), enables exposing arbitrary block and file storage systems: this means that by using CSI third-party storage providers can write and deploy plugins exposing their storage systems.
A Quick Walkthrough
It has come the time to treat ourselves a little bit of fun - let's have a go on our brand new RKE2 Kubernetes cluster: as a demo we will deploy the "kubernetes-bootcamp" container and add an ingress rule to reach it from the outside world.
The prerequisites for this to work are:
- the "kubernetes-bootcamp.carcano.corp" FQDN must resolve to the Load Balancer IP we assigned to the ingress controller ("10.211.55.10" in this post)
- the TLS secret "carcano.corp-wildcard-cert" contains a certificate signed by an CA trusted by the client we will test the connection from (using a curl statement)
First, create the "playground" namespace:
kubectl create namespace playgroundthen, create the "kubernetes-bootcamp" deployment in the "playground" namespace
kubectl create -n playground \
deployment kubernetes-bootcamp \
--image=gcr.io/google-samples/kubernetes-bootcamp:v1let's have a look to the "playground" namespace's contents:
kubectl -n playground get allthe outcome must look like as follows:
NAME READY STATUS RESTARTS AGE
pod/kubernetes-bootcamp-77689f7dbf-cl4hp 1/1 Running 0 8s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/kubernetes-bootcamp 1/1 1 1 8s
NAME DESIRED CURRENT READY AGE
replicaset.apps/kubernetes-bootcamp-77689f7dbf 1 1 1 8sthen, create the cluster service for balancing it within the Kubernetes cluster:
kubectl -n playground expose deployment/kubernetes-bootcamp \
--type="ClusterIP" --port 80 --target-port 8080let's check the services details:
kubectl -n playground get svcthe outcome must look like as follows:
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-bootcamp ClusterIP 172.30.7.62 <none> 80/TCP 14slastly, let's create the ingress rule to have the ingress controller forwarding the traffic for the "kubernetes-bootcamp.carcano.corp" to the "kubernetes-bootcamp" service on port 80:
kubectl -n playground create ingress kubernetes-bootcamp \
--rule="kubernetes-bootcamp.carcano.corp/*=kubernetes-bootcamp:80"If everything properly worked, and the requirements we previously are all met then from any host, we must be able to run the following curl statement:
curl https://kubernetes-bootcamp.carcano.corpand get a reply that looks like as follows:
Hello Kubernetes bootcamp! | Running on: kubernetes-bootcamp-77689f7dbf-cl4hp | v=1Footnotes
As we saw, installing a highly available RKE2 Kubernetes cluster is quite an easy walk. I hope you found this post insightful, and you got how this distribution can really ease your life as a sysadmin.
If you appreciate this post and any other ones, just share this and the others on Linkedin - sharing and comments are an inexpensive way to push me into going on writing - this blog makes sense only if it gets visited.

Fanis says:
Great and very detailed tutorial! Keep up the good work!
Marco Antonio Carcano says:
Thank you Fanis, … will do