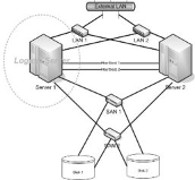
Some businesses are so sensitive to service outages to require a 24×7 Service Level Agreement. Guaranteeing 99.999% of uptime means a cumulative service outage of not more than 5 minutes per year. This impressive goal can be achieved by setting-up High-Available clusters.
Linux professionals should have a very good understanding of clustering, being able to guess the right cluster type that should be setup – Opt-in (asymmetrical) or Opt-Out (symmetrical) – and the clustering mode suitable for each service (Active-Active, Active-Passive).
Of course this requires be skilled on several softwares, such as:
- Corosync – cluster engine
- Pacemaker – cluster resource manager
Often it is required also to set up redundant filesystems; these are often but not always clustered: this deeply depends upon the particular use case. So Linux professionals should so also be skilled onto:
- DRBD – a kernel module to replicate block devices over the network
- Setting the proper LVM locking type when not using clustered file systems
- Clustered LVM – enabling the distributed lock manager on LVM
- GFSv2 – a clustered file system
In addition to that, having a good understanding of Gluster – a resilient and replicated storage suite – may certainly help for some kinds of workloads.